Description
For developing the universal platform and introducing it in DBpedia’s existing ecosystem, the last two years (GSoC 2020 and GSoC 2021) were about Proof of Concept (PoC) and building the foundations of the platform. In GSoC 2020, the dashboard for DBpedia was for summarizing the data statistics of the public endpoint. The SPARQL queries were referenced from the paper SPORTAL: Profiling the Content of Public SPARQL Endpoints. However, in GSoC 2021, several components were added to introduce more usability.
At present, the new platform for data and knowledge engineering includes following capabilities:
- User authentication with credentials same as databus.
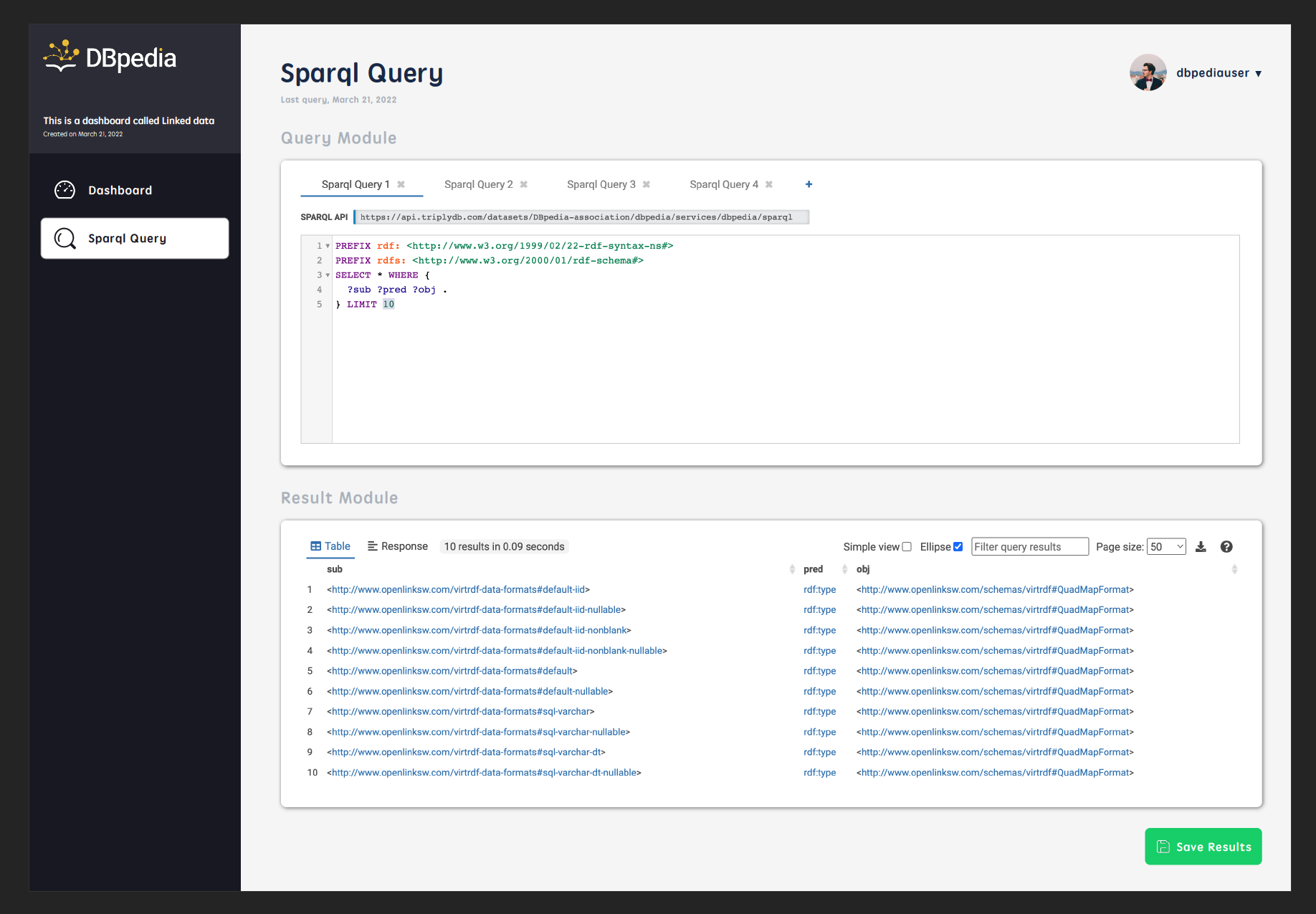
- Integrated web based SPARQL query editor YASQE on the platform that allows users to query different endpoints and save their results.
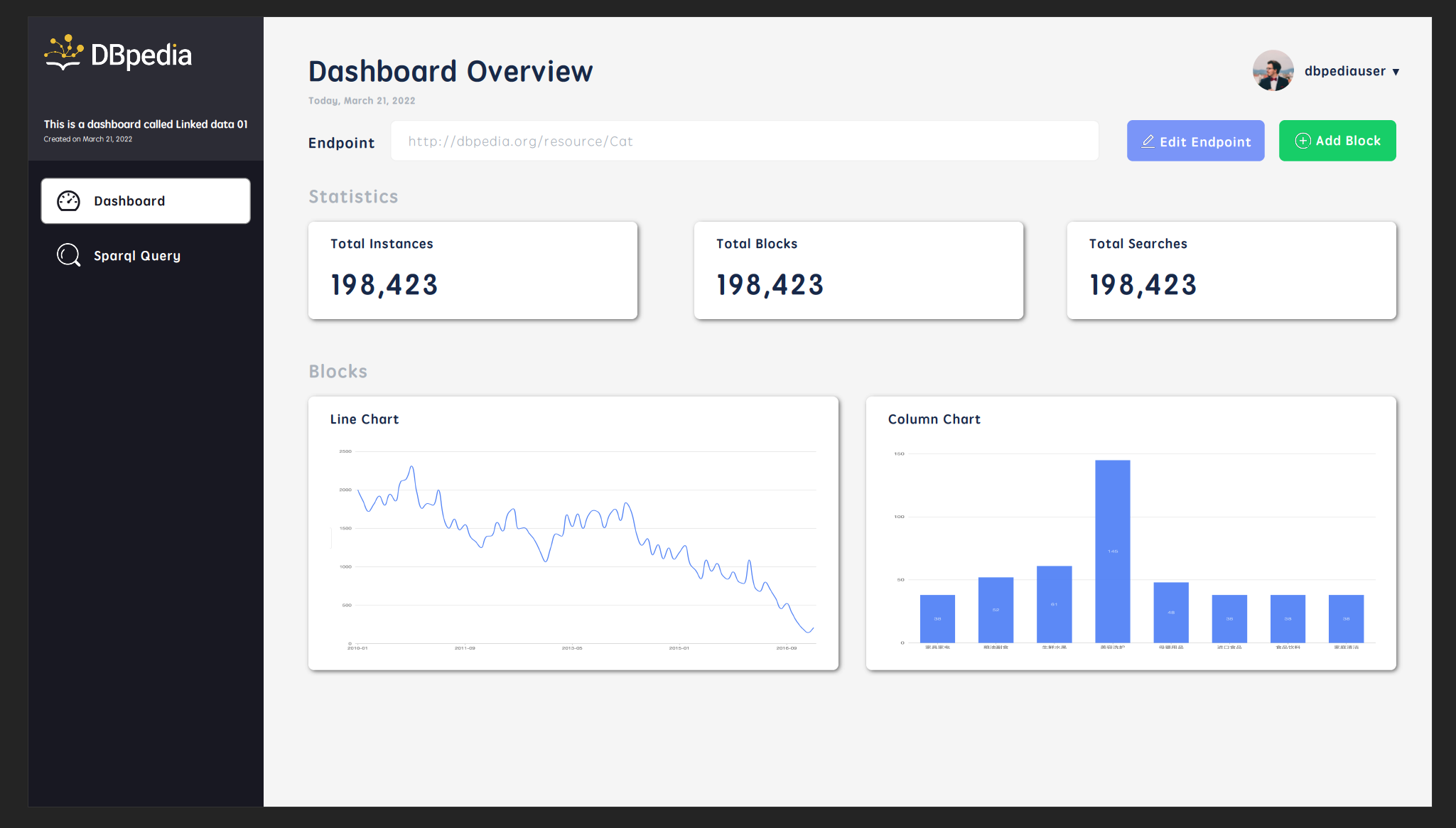
- Visualize query results (based on user selection: pie chart, line chart, bar chart, etc.) and add such multiple blocks on the blank canvas to publish it as a complete custom dashboard.
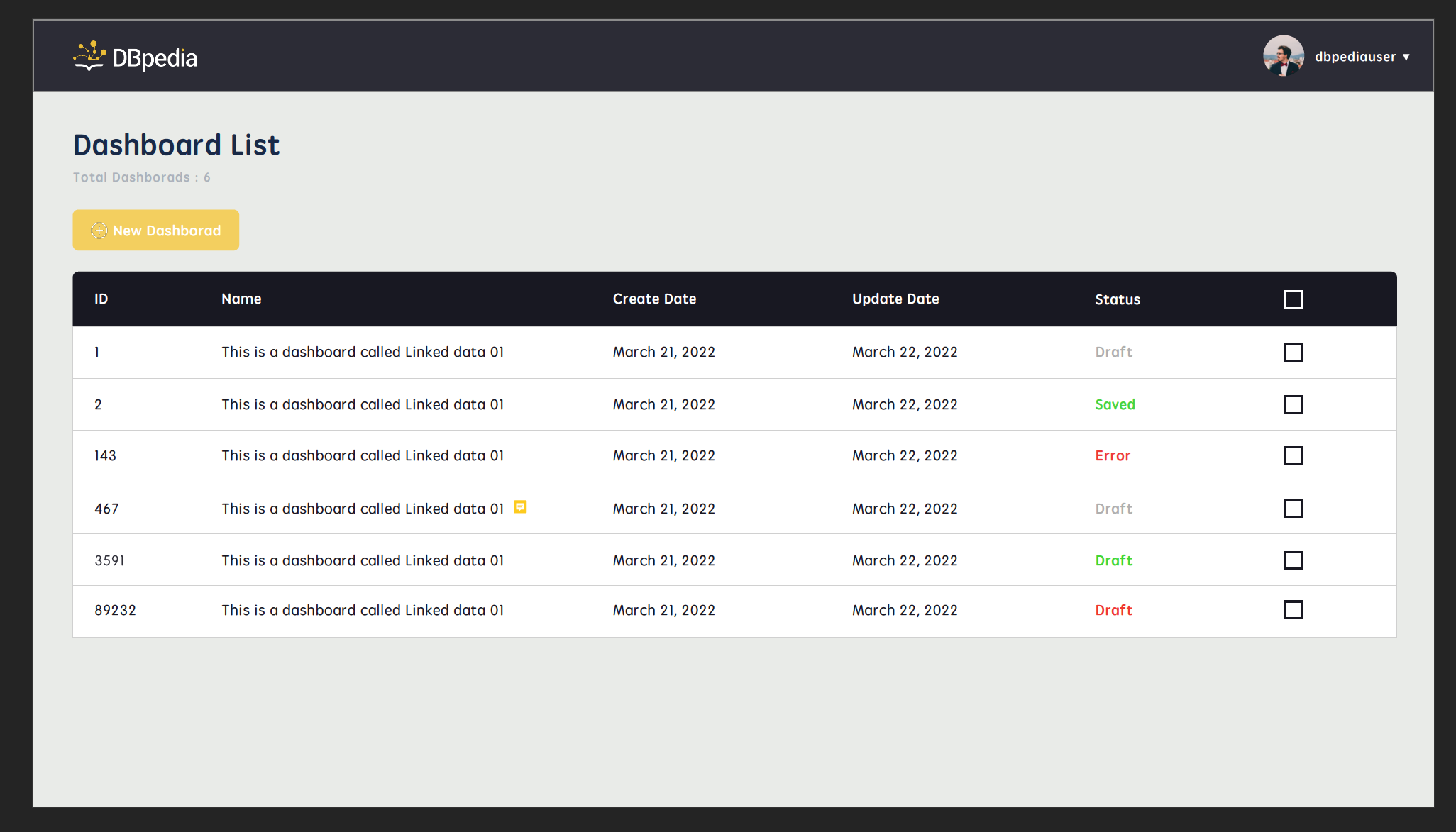
- Create, View, Update, and Delete dashboards and their internal blocks.
Few screenshots of current stage of project:

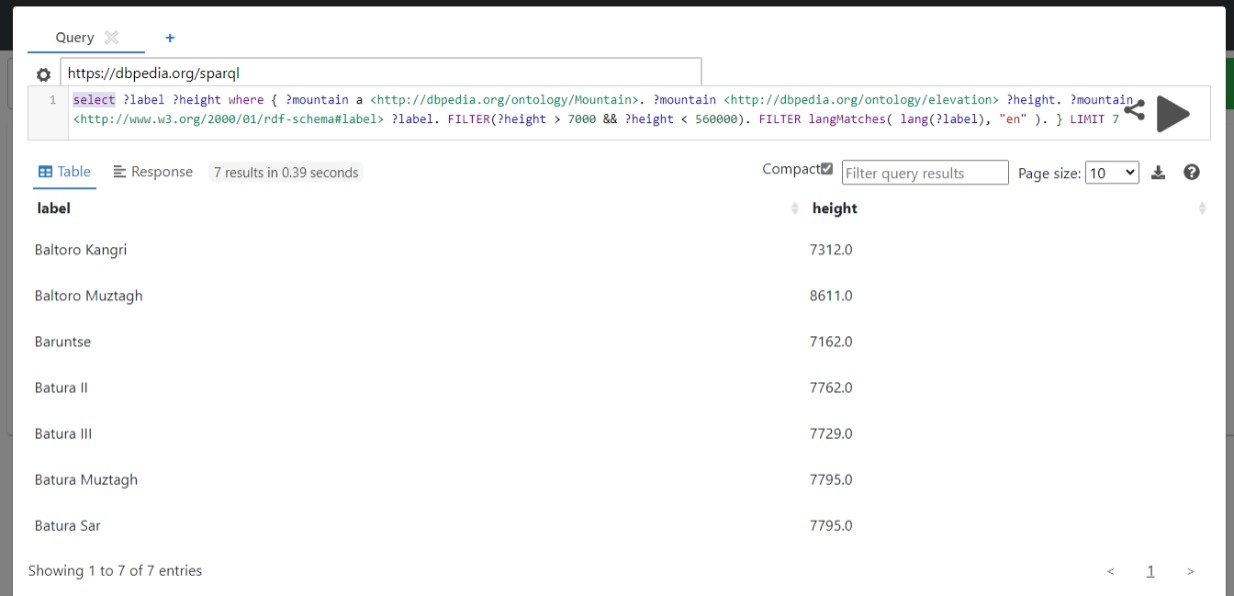
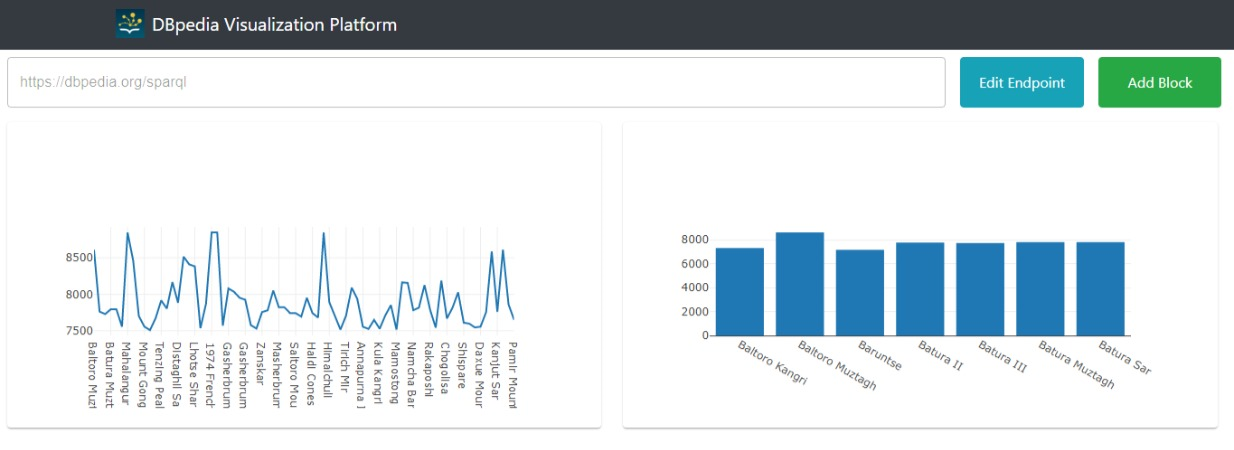
This year, the project is about stabilizing the existing functionalities, including fixing UI using ReactJS, and filling gaps in CRUD operations in MongoDB using Python web framework Flask. Additionally, for building blocks in dashboards, several components are used like YASQE, Plotly (for visualization), and Bootstrap. These components need to be tightly integrated to work efficiently. For visualization, introduce new graphs and options to change characteristics like color and size of blocks. Lastly, using docker, deploy the platform on DBpedia server.
Goal
The goal is to build an official staging area for small data transformation and visualization to perform analysis without leaving DBpedia’s ecosystem. The phases of data lifecycle includes fetching the data from user defined endpoints (multiple or single), apply aggregate functions, select visualization characteristics and lastly, publishing the results.
Impact
-
User Retention: Users that rely on DBpedia’s data, are fetching by querying and lastly analyzing it on other platforms. With that being said, there is not much interaction between users and DBpedia’s knowledge graphs as processing is done completely outside of DBpedia which leaves DBpedia, just a data-hub. However, having this platform integrated in existing ecosystem will help users to manage as well as analyze their data without shifting away from DBpedia. With this, users can leverage all the support from the community in terms of data processing.
-
Better Control Over Knowledge Graph Statistics: As users will query and filter the data to visualize it in their ways, it gives more flexibility for custom operations. Additionally, users will be able save their files (output of queries) in their buckets (folders) on the dashboard portal itself.
Warm-up tasks
- Getting familiar with Docker, ReactJS, and Flask (Python). Setting up the local environment of current project GSOC2021-DBpedia
Note: Good to have DBpedia databus account registered. - Spinning up docker containers locally.
- Setup local MongoDB container and include that as a part of docker-compose for the project.
- Getting started with redesigning login page.
Mentors
Jan Forberg
Karan Kharecha
Project size (175h or 350h)
350h
Keywords
docker, data engineering, knowledge graphs, user centric, user authentication, data visualization