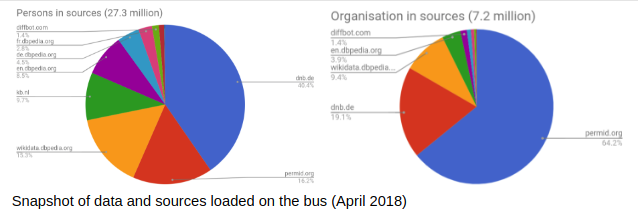
we redid and evaluated the fusion of DBpedia only:
“DBpedia FlexiFusion The Best of Wikipedia> Wikidata> Your Data”, J Frey, M Hofer, D Obraczka, J Lehmann, S Hellmann at coming ISWC 2019
Note that the paper carries “Your Data” in the title, because we knew from before that we could load KB, DNB, Permid, but it is not the focus of the paper.
Now we are in the present with these todos:
a) Not all external datasets are easy to integrate. We are doing a categorization similar to OntoClean, but under integration aspects. We call them SyncTargets and are a topic in the GlobalFactSync Project. I think, we pinged you for recent news, you should sign up as a volunteer. Then pitch permid as a sync target for complementing a concrete part of Wikipedia infoboxes and Wikidata.
b) we need to stabilise and improve DBpedia data, we already fixed a nasty URI encoding bug. Then we will republish the FlexiFusion dataset several times per year.
c) we are discussing to integrate the R2R framework into the Databus Client (very alpha) which has operations like download the latest version of these 10 artifacts compressed as bz2 converted to ntriples into this graph database. With the update “mapped to DBpedia ontology where equivalentProperties are found”.
Are the entities matched across datasets?
Databus has agile processes with iterations and continuous integration. We are developing a 4 or 5 star rating to improve linking over time. One example: after the fusion, you can better see the linking errors, delegate to a previous artifact and fix them there for the next version, which will be used for the next fusion.
I have to admit that we still lack details on how to collect and debug links yet, but we cracked it for the extraction framework: Anything you fix now, will have an effect in one month for the next Marvin release. Ideally, you delegate all errors directly to the ci tests on the minidump using mvn test, sorry these are mostly undocumented right now, but @jimkont tries to find some free time to integrate the RDFUnit SHACL engine for on commit Travis tests.
So here it is: 1. String validation (encoding/uris), 2. RDF parsing, 3. SHACL