Greetings all,
We need to use the dbpedia spolight model to do some batch inferencing on ~5M documents. As such, the docker file and a REST API endpoint won’t be useful here because we don’t need a prediction service. We need the underlying model code (I believe it is written in scala) to execute the predictions and we will likely be using a distributed computing framework like Spark to process the 5M documents.
It is true that we could create a REST API and send the 5M documents asynchronously through the annotation endpoint, but that would take a long time and we would be dealing with latency and networking bandwidth issues.
Any help on how to get started on this? I see the underlying model code is in this github repo: https://github.com/dbpedia-spotlight/dbpedia-spotlight-model. But there are no instructions on how to run the model outside of setting up the docker service.
Thanks,
Riley
Hi @rileyhun
Thanks for the post. The project described sounds really interesting. And yes, the underlying model code is in the posted repo (https://github.com/dbpedia-spotlight/dbpedia-spotlight-model).
For example, to run the model with IntelliJ:
- Clone the DBpedia-spotlight-model (git clone …)
- Open the project on IntelliJ (File → Open)
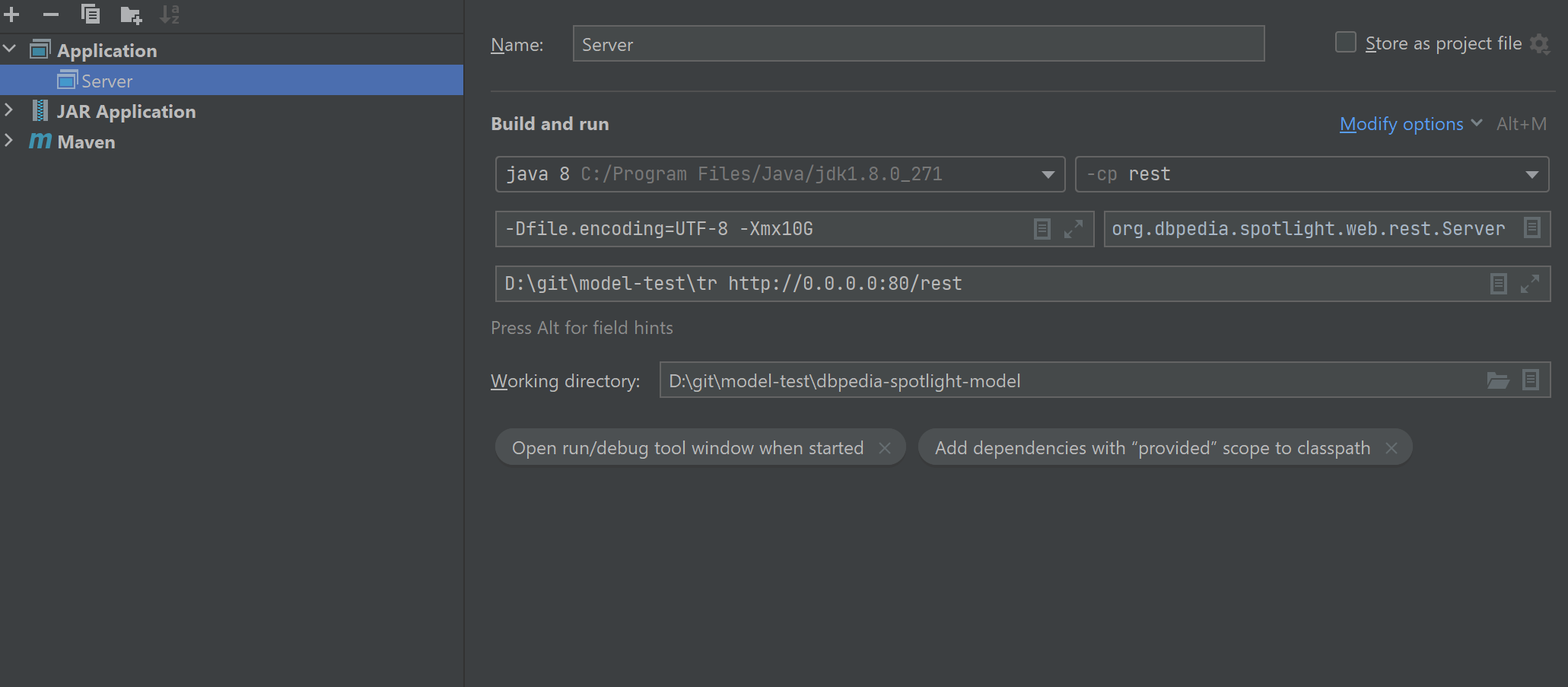
- Create a configuration to run DBpedia Spotlight (Run → Edit configurations)
3.1 Create a new Application configuration
3.2 Set the fields as the following image (changing the paths with your own):
The D:\git\model-test\tr is the path of the extracted model and http://0.0.0.0:80/rest is the URL of the service. I hope this information helps. Have a great day.
My best regards
Julio
Hello @JulioNoe,
Thanks for your prompt response. The example you showed above is still running the model through a web server. I basically just want to extract the model code and be able to execute the annotation from the code-level, not as a REST API endpoint. So basically, is there a way to just extract the model code, and run the annotation method/function?