“An example of an excellent proposal that was accepted a few years ago. Please mind that the number of total project hours have changed from 300 to 175.” Tommaso Soru
Hii, @emarx I’m an undergrad student from India and been working on NLP and Knowledge graphs in my recent project related to news co-relation. I’m highly interested in this project, starting with the warm-up task. Looking forward to a great learning experience with you.
Hii, @emarx in NSpM I generated the dataset using the monument_template. I got the flow of how the template.csv is broken down in annotations and then annotations are passed to generate the query and that query is then used to fetch the result and from those bindings are used to generate a pair of en_question and SPARQL, but I don’t get the complete hang of
“prepare_generator_query(template, add_type_requirements=True, do_special_class_replacement=True)”
like how the complete working query is created and what type of queries are there, so if there’s any documentation or examples for such queries it will be helpful.
correct me if i’m wrong somewhere with the flow.
Thanks.
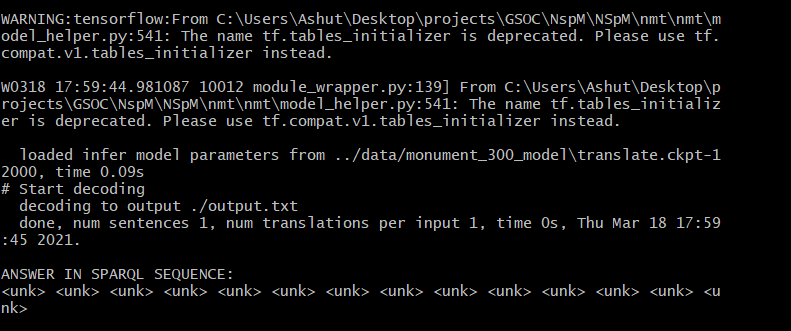
hi @emarx I’m almost done with task1… trying to generate the query, I understood the flow of training the translation model from the paper and also the architecture of the attention model used, but while I’m generating the SPARQL using English through model it gives tokens out of vocab i tried using train data as well the result is same. what’s the problem here?
Also for warmup task 2, there are different datasets in DBNQA like (art, sport,etc…) so for training shall I use the first 30 lines from all the files or from any specific file like the last one was for monuments?
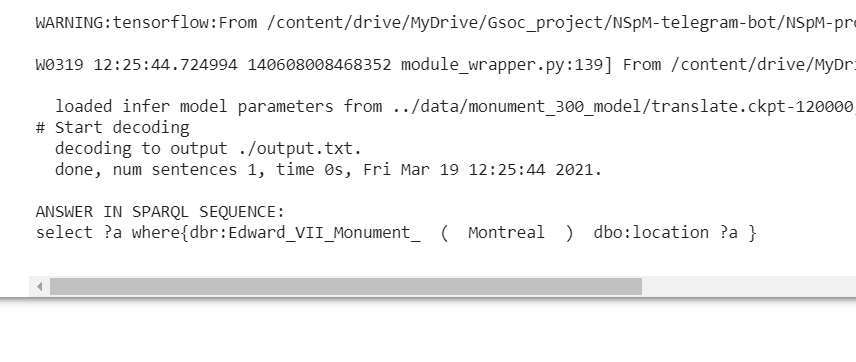
update on this one, I wasn’t able to get the output from the model I trained from NSpM “https://github.com/AKSW/NSPM” repository so instead, I cloned the
" https://github.com/AKSW/NSpM/wiki/NSpM-Telegram-Bot " repo which had pre-trained models used this one to generate the query but the code was in python 2 so converted it to python3 and now I’m able to get the right query.
Meeting ID: 971 7701 8759
Passcode: dbpedia
One tap mobile
+16468769923,97177018759# US (New York)
+16699006833,97177018759# US (San Jose)
Dial by your location
+1 646 876 9923 US (New York)
+1 669 900 6833 US (San Jose)
+1 253 215 8782 US (Tacoma)
+1 301 715 8592 US (Washington DC)
+1 312 626 6799 US (Chicago)
+1 346 248 7799 US (Houston)
+1 408 638 0968 US (San Jose)
Meeting ID: 971 7701 8759
Find your local number: https://eccenca.zoom.us/u/adeQxEg4QS
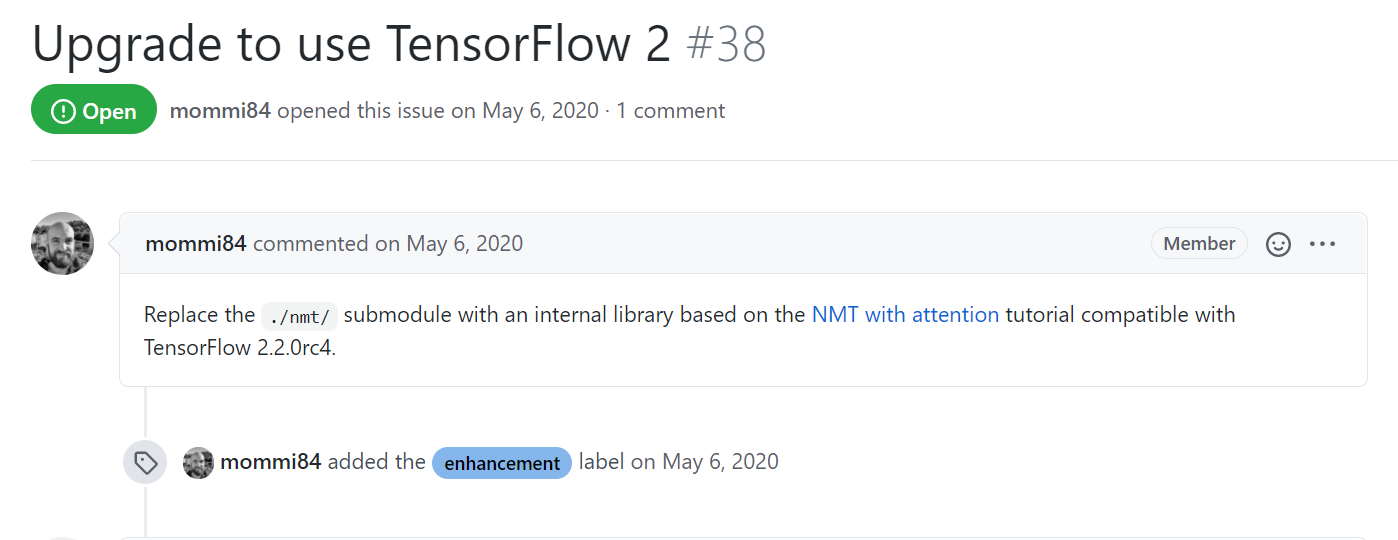
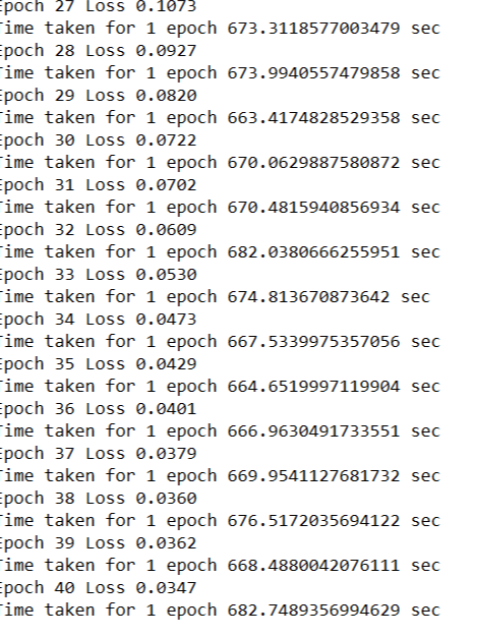
and it’s working fine with TensorFlow 2.1.0 I have changed few files and removed some but the end result is same.it can be improved further and pipeline can also be made better but currently this works fine though training time is large.
Hii, @emarx I’m a junior undergrad student from India and been working on NLP. I’m highly interested in the project, starting with the warm-up task. Looking forward to a great learning experience with the team.
Hi @emarx I’m currently a final year undergrad from india.I’ve been working on few ML problems till now and have two internship experience.And for GSoC I’m interested to work in this project.I’m starting with the warmup task.Hoping for a great learning experience with you.