DBpedia has done a great job of collecting and organizing data. Data accessibility is the key to a better understanding of the world and a foundation of Data Literacy, a crucial competence for the current generation. In 2021, a DBpedia GSoC project [1] led to the development of a Dialogflow-based chatbot that enables users to access the DBpedia Knowledge Graph (KG) using Natural Language (NL). The chatbot provides Question Answering (QA) functionality, i.e., searching for facts that are answering NL questions. During the GSoC 2023, we will continue the DBpedia Chatbot initiative.
The core idea of the DBpedia eXplainable Chatbot – short: DBpedia XChat – is to be configurable on-the-fly. Users can choose components that process a question (i.e., SpaCy, Falcon), change working language, and also get explanations regarding the intermediate processing steps and components’ behavior.
The current architecture of the DBpedia Chatbot consists of three layers:
- Google Dialogflow frontend — generates the UI and handles the intent recognition logic (developed using Google’s platform)
- DBpedia Chatbot backend — handles requests from the frontend regarding the general intents: “hello!”, “what can you do?”, and custom features: change language, choose QA components, etc. (developed with JavaScript and Python)
- Qanary QA framework [2] — orchestrates the QA components and does the QA process if a question is fact-oriented, e.g., “Who is the CEO of Google?” (developed with Java and Python).
The activity diagram below demonstrates the interaction of the architectural layers of the Chatbot.
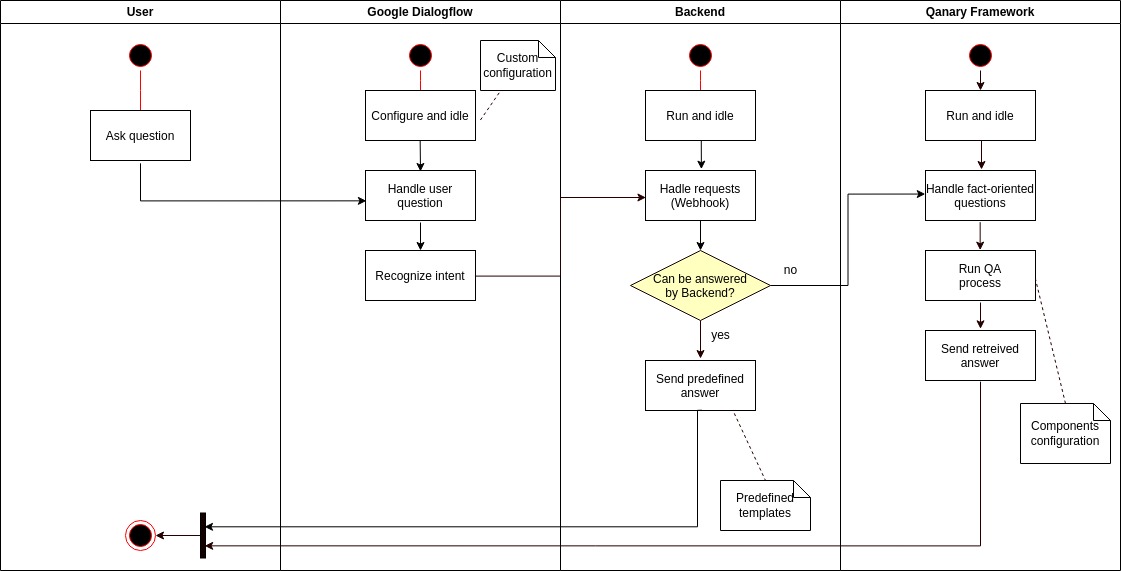
Figure — Activity Diagram of the DBpedia Chatbot’s architectural layers
This year, we are going to tackle the unsolved challenge of the DBpedia Chatbot and hence, define the following goals:
- Work with the current codebase.
- Refine and prettify the current codebase (s.t., the code becomes readable and supportable)
- Setting CI/CD for the solution using a public server (will be given by project supervisors)
- Introduce new features to the chatbot.
- Provide a user with better access to internal information, s.t., the Question Answering process becomes a “glass box” instead of a “black box”. For this purpose, new dialog scenarios need to be created with additional visualizations or rich responses.
- Implement a dialog scenario to get an overview of the Qanary QA pipeline configuration and of its components.
- Implement a scenario, where for each Qanary Component, a user should be able to see detailed information and description.
- Optionally, a visualization of the QA pipeline (ASCII-art or better) would benefit users.
- Evaluation of the DBpedia chatbot.
- Validate the answers by measuring the Question Answering quality.
- Run A/B tests with real users to understand how explainability influences users’ satisfaction.
- As the overall goal is to improve the answer quality, additional Machine Learning components might be used to create recommendations for improved QA pipeline configurations (e.g., if a component has a low confidence score, then another one should be suggested).
- In detail, this means that you might run different pipeline configurations while training to then start the best-suited pipeline on test time. Here, a simple, hugging face-based LLM fine-tuned on a large dataset such as LC-QuAD 2 or GRAIL-QA could be used.
The impact of this work would be:
- Refinement, stabilizing, and setting CI/CD for the current codebase.
- Integration of explainability/traceability of search results (“glass box” behavior to help users to understand the search behavior).
- Identification of typical misbehavior of the chatbot and creation of requests for improvements of processing steps that might fail often.
- Scientific study on the impact of the explainability feature on users’ satisfaction with the system.
Warm-up tasks:
- Create a Google Dialogflow account and implement a Google Dialogflow tutorial: Tutorials & samples | Dialogflow ES | Google Cloud 7
- Get familiar with the DBpedia Chatbot (from GSoC 2021): Modular DBpedia Chatbot GSoC 2021 | DBpedia-GSoC-2021, https://github.com/dbpedia/dbpedia-chatbot-backend, https://github.com/UditArora2000/GSoC2022_Question_Answering and GitHub - dbpedia/chatbot-ng: Repository for the GSoC 2021 project 'Modular DBpedia Chatbot'.
- Run the previous year’s code: GitHub - UditArora2000/GSoC2022_Question_Answering
- Run simple SPARQL Queries on DBpedia to get familiar with the data and the technology (e.g., via Yasgui).
- Execute requests to the Qanary pipeline using Python or JavaScript (see this example and the guides at [3]).
- Optional: Read the tutorial on implementing a trivial Qanary-driven question answering pipeline (cf. https://qanswer.github.io/QA-ESWC2021/slides.pdf 1).
Requirements for applicants:
- Good knowledge of Software Engineering
- Fluency with Python and JavaScript
- Good understanding of RESTful APIs and ability to implement one
- Experience with Natural Language Processing (e.g., University Projects)
- Understanding of Resource Description Framework and SPARQL
- Basic knowledge of Shell scripting (e.g., ssh connection to a server)
- Basic understanding of CI/CD: Docker, GitHub Actions
The project size can follow the medium (~175 hours) or large (~350 hours) format. However, we prefer the large format as it provides more opportunities to increase the impact.
Mentors:
Please, express your interest here at the forum or use the Github accounts listed above. Also, feel free to join the DBpedia Slack workspace by visiting Slack and write us there.
Scientific Contribution: We are open to working together with the project participant on preparing a scientific publication based on the project results targeting top-tier conferences (WWW, ESWC, ACL, etc.).
Keywords: Question Answering, Natural Language Processing, Natural language Understanding, Named Entity Recognition, Machine Learning, Explainable AI, Knowledge Graphs, Linked Data, Semantic Web, Python, JavaScript.
References:
[1] GSoC 2021 project: Modular DBpedia Chatbot
[2] GitHub - WDAqua/Qanary: Qanary a methodology to construct and share resources to build QA systems