We have been using a subset of files of the 2016 DBPedia dump to illustrate the capabilities of a semantic data exploration tool called Rhizomer. The subset includes just those parts that facilitate the user experience when exploring DBPedia with Rhizomer without overwhelming the user with too much information.
The details about the subset of the 2016 dump we are using are available from:
We would like to use the last version of DBPedia dumps but exploring the mechanisms to download DBPedia available now, we haven’t been able to see a clear connection between the files we were using and those available right now. Any guidance about how to proceed to get a similar subset of DBPedia using the new download mechanisms would be highly appreciated.
By the way, you can explore DBPedia using Rhizomer at: RhizomerEye
Hi @rogargon,
two things at the beginning: 1. Could you correct DBPedia to DBpedia wherever you find it (also Rhizomer docu), 2. I am writing some Databus things below, but we will soon release Databus 2.0 which has some small, but breaking changes, so could be that you need to update some things later, when this happens.
Other than that the use case you have is one of the main features of the Databus. DBpedia is now extracting 5000 files monthly and nobody needs all of them. So we refactored the releases into a Maven structure. I had a look at Rhizomer and it also uses Maven in the RhizomerAPI. Databus works similar to software dependency management in Maven using a user/group/artifact/version/file structure.
For each file from the list, you need to select the appropriate artifact and version. Instead of writing <dependency><group><artifact>etc in the pom.xml things can be shortened with sparql. I made a query which covers your 18 files, see this link. Note that images are missing and abstracts are old. the latter is being fixed now. Or well you could switch to the dev artifacts: https://databus.dbpedia.org/vehnem/text/short-abstracts and https://databus.dbpedia.org/vehnem/text/long-abstracts
Another option is to 1. register at databus.dbpedia.org and 2. use the collection feature. It is like a shopping cart, where you can aggregate all files you need under one collection URL. This is what we did for latest-core. You could make a stable collection for Rhizomer once a year.
A further notice is that we build a Databus Client to help with conversion. It has a download as function, i.e. you pass it the query or collection url and tell him that you would like the files as gzip and the client will convert on download.
We use images in the user interface whenever they are available, are they going to be included at some point?
Regarding databus-client, we tried to build it but we are getting the following error in an EC2 instance with Java 8 (also tried Java 11) and Maven 3.8.1:
Nice. A small tip regarding the URL of https://databus.dbpedia.org/rogargon/collections/browsable_core . Here it is ok to put version info into the URL, e.g. you could call it browsable_core_2021 and then do browsable_core_2022 or you could make it dynamic, i.e. update browsable_core to always point to the latest working subset. But this decision is up to you.
Regarding the Databus client problem, Databus is also fully bash compatible for downloading:
query=$(curl -H "Accept:text/sparql" https://databus.dbpedia.org/rogargon/collections/browsable_core)
files=$(curl -H "Accept: text/csv" --data-urlencode "query=${query}" https://databus.dbpedia.org/repo/sparql | tail -n+2 | sed 's/"//g')
while IFS= read -r file ; do wget $file; done <<< "$files"
So you could also use this or rewrite it to do the bzip2 to gzip conversion.
@eisenbahnplatte can you look at the problem. This seems to be like a very good use case for the Databus Client, but it can’t be compiled?
@rogargon I tried to reconstruct the exception you got, but with no success.
my Java Version: 1.8.0_292
Initially I used Maven 3.3.9, but I switched to 3.8.1 to see if that works too, and it does. I also deleted my maven .m2 folder to see if maven downloads all the dependencies correctly.
Did you mvn clean install first? Otherwise some dependencies may are missing for you.
Apart of that I made minor changes, because there was an issue with the handling of Collection Queries. The following commands work fine for me now.
Another approach would be to use the released jar file of the DBpedia Databus-Client. Have you tried that already? It works out of the box, no maven commands needed. You can download it here:
Hi,
I tested it on the DIEF minidump (a small subset of Wikipedia to test extractions), and it worked.
I will try to run the complete image extraction for the June dumps and publish it.
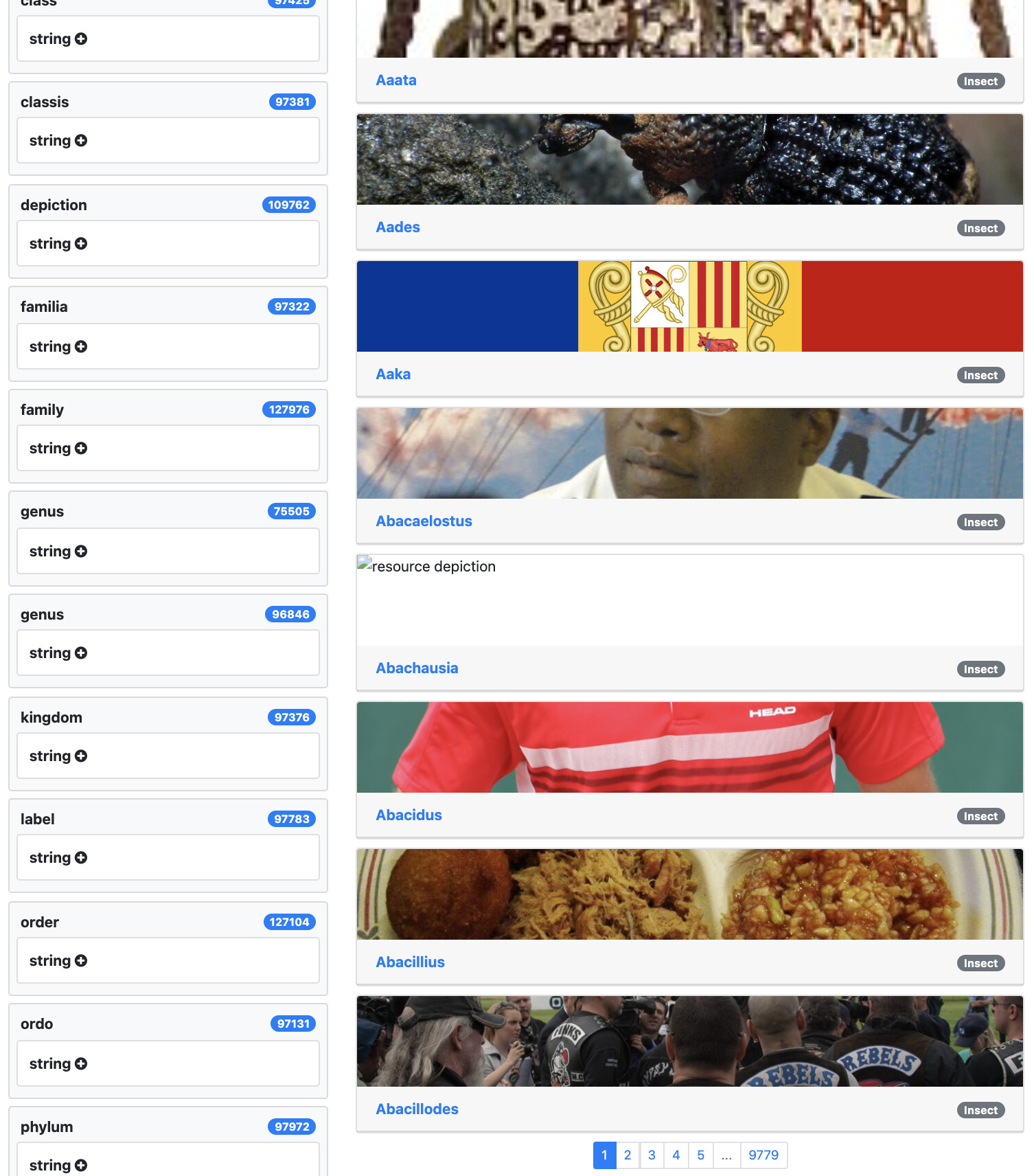
Regarding the outcome, there seem to be some issues with images. For instance, for the first 10 insects, just 3 of them seem to have a picture of the actual insect: RhizomerEye
Moreover, looking to further simplify the UI, there are many properties that are repeated in the DBpedia Property and DBpedia Ontology namespaces (i.e. dbp and dbo). Are they kept separate in different dump files so I can choose to just load those from dbo?
Hello, attaching a screenshot of the page showing the issues with images, as we are going to revert to the old dump and it will not be visible at the previous link.
As it can be observed, just the two instances at the top have images that correspond to insects:
One way to download specific parts of DBpedia is to use the DBpedia extraction framework and select the datasets or subsets that you are interested in. The DBpedia extraction framework is a set of scripts and tools for extracting structured information from Wikipedia and publishing it as Linked Data.
To download specific parts of DBpedia using the extraction framework, you can follow these general steps:
Choose the datasets that you are interested in. DBpedia provides a wide range of datasets, such as the core dataset, which contains information about concepts and their properties, the ontology dataset, which describes the DBpedia ontology, and the mapping-based dataset, which contains information extracted from Wikipedia infobox templates.
Download and install the DBpedia extraction framework. The extraction framework is available on GitHub and can be installed using Maven.
Configure the extraction framework to extract the datasets that you are interested in. You can do this by editing the configuration files, which are located in the “extraction-framework/config” directory.
Run the extraction framework to extract the datasets. You can do this by running the “run” script, which is located in the “extraction-framework” directory.
Once the extraction is complete, you can access the datasets in the output directory, which is specified in the configuration files.
Note that the extraction process can be time-consuming and resource-intensive, so it may be helpful to use a server with sufficient computational resources to perform the extraction. Additionally, you should ensure that you have permission to use the data in the way that you intend, as DBpedia is licensed under the Creative Commons Attribution-ShareAlike 3.0 license.