So the first question is: what is the last update for the online DBPedia?
Now I want to create my Virtuoso installation from these models, because I need to run sparql query on the new entities, but I don’t understand which kind of files are needed to feed virtuoso and run SparQL query.
Thanks @jfrey
it seems that databus-download-min is removed from docker hub, so the docker-compose doesn’t run.
I fixed the docker-compose and make a pull request [1].
The databus-download-min is moved to [2] as the link in the github project page [3]
Ok thank you. Just for the record: databus-download-min is the local image name which requires that the image is built locally before. But there is only a hint for this step in the docu, not very user-friendly ;-). I think it would actually make sense to fetch both images from dockerhub and use an override compose file to build the images locally in case it is needed. That is why I did not accept your PR so far because we need to discuss that. But thank you for reporting the issue.
If I run the virtuoso endpoint whit the docker-compose I don’t have any result, if I run this query on live.dbpedia.org I have the result I want.
Why? Can you help me with this?
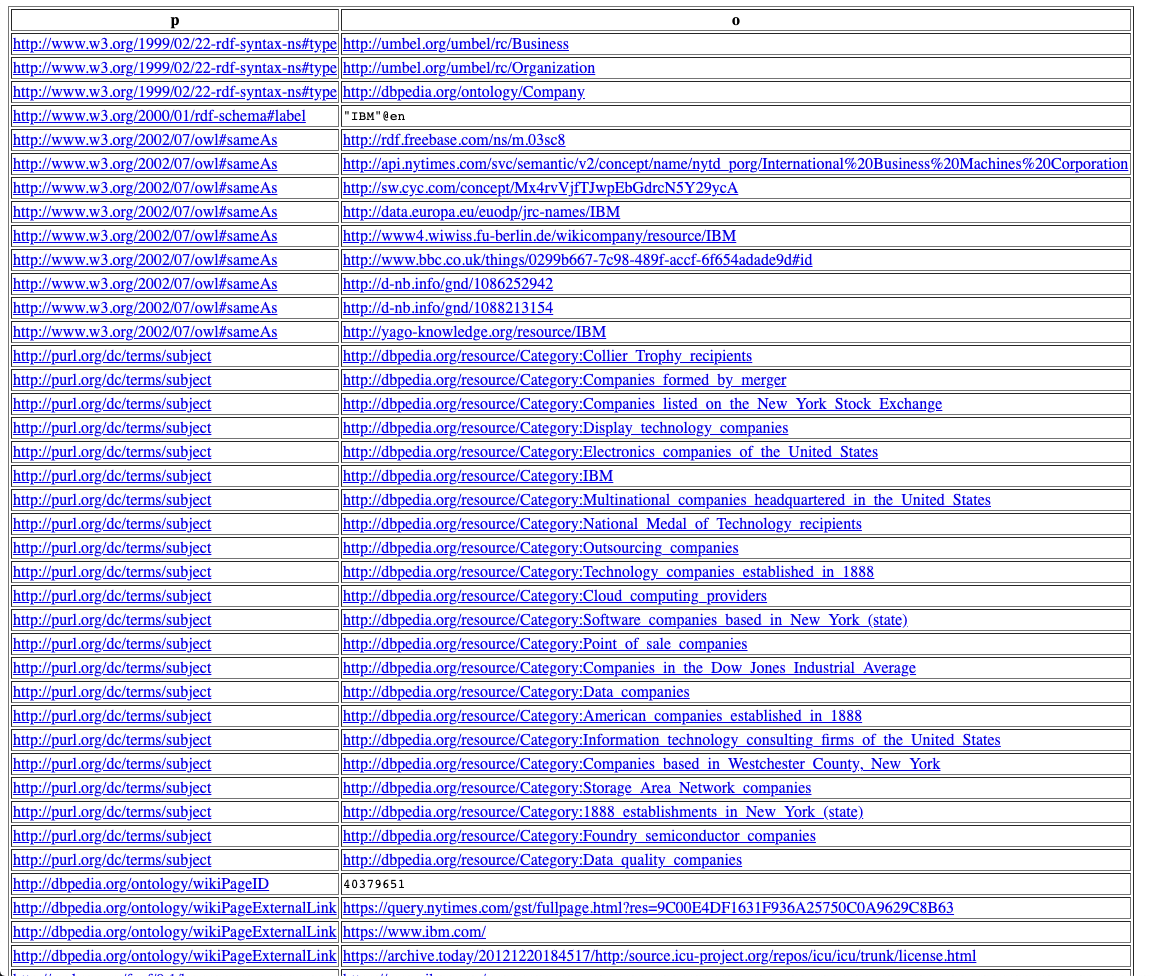
Select * where {
<http://dbpedia.org/resource/IBM> ?p ?o.}
I had a look and the English mapping files from 2019.09.01 do not contain a single triple for IBM. So if the query from above returns some triples you did not do anything wrong. I guess this is cause by something I wrote here Local vs online dbpedia versions: different results are returned
Alright. I am a bit surprised about this one rdf:type dbo:Company triple but apart from that there seems nothing wrong on your side. You can only wait until a new release is performed or combine 2019.09.01 with the 2016-10 release or use DBpedia Live mirroring[1], @kurzum what what is the status about 2016-10 release on Databus and does Live Mirroring still work out of the box after redeploy of live?
@klaus82 seems like you received some very complicated answers, although you have one of the most basic use cases, i.e. create a mirror of DBpedia.
Let me answer this:
setting up a DBpedia Live Mirror is extremely complicated. Do not try that. @jfrey please stop suggesting this to people, unless they specifically ask about it. It is extremely hard and time-consuming.
[RECOMMENDED] @janfo could you hurry your two tasks and try to finish them? The first was to refactor the pre-release collection into a latest collection. The second is to make the Dockerized DBpedia run with collections smoothly. This is actually what @klaus82 wants and it coincides with what we are doing currently.
@klaus82 If you don’t like the collections we create, you can always a) create a databus account, b) create your own collection or copy an existing and modify it. Note that they are all loaded into the same graph per default. So any duplicate triples should disappear.
Please use it with this dockerized dbpedia container:
The query of the collection will fetch the latest release, we are working on static collections (selecting a specific version) for the public endpoint.
As far as I understood, the problem is that the releases used in the collection so far miss for @klaus82 important data. The question now is which one of the solutions fits best for his use case. @klaus82 please let us know what you actually want to do. If you only like to retrieve data per entity and no “analytical” query then I could write how to perform solution 2 (ad-hoc extraction). I doubt that the collection @janfo posted will bring you the data you are interested in since it is still using an old release at the moment (2019-09-01)