Name: Shreya Singh
Email: shreyasingh38207@gmail.com
Time zone: GMT+5:30
Project Description: It is basically the synthesis and analysis of natural language and speech. In this the human language is separated into fragments so that the grammatical structure of sentences in the meaning of words can be analyzed and understood in context. This helps computer to read and understand spoken or written text in the way human does.

Aspects Targeted Through Project:
- Text and Speech Processing: The first thing will be done in this task that the text and speech will be processed in a way that computer is able to understand languages which human does.
- Morphological analysis: It is the problem-solving ability or exploring solutions to any problem.
- Syntactic Analysis: It is the logical meaning of certain given sentences
- Lexical Analysis: It is the first phase of compiler that converts the high-level input program into a sequence of tokens.
- Relational semantics: It is the relation between words for better understanding
- Discourse: It is a coherent structure of the textual units.
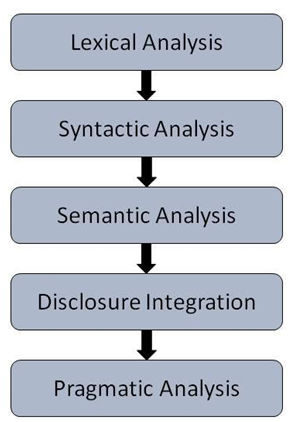
All these features will be implemented in this project and so that the computer can understand the human languages. With these features we will be adding a feature that our computer can understand the actions which a human understands.
Components involved in Natural Language Processing:
The components involved in Natural Language Processing are language API’S and Libraries are:
- IBM Watson API: It uses different machine learning techniques which enables text into various custom categories. It can understand many languages like French, German, Spanish, Chinese etc. With the help of this API, we can extract insights from text, add automation in workflows, enable search and understand sentiments.
- Chatbot API: It allows you to create intelligent chatbots for any service. It supports Unicode characters, classifies text and many languages. It helps create chatbot for web applications.
- Speech to text API: It converts speech into text.
- Sentiment Analysis API: It is also called opinion mining which is used to identify the tone of user (positive, negative or neutral).
- Translation API: The translation API by SYSTRAN is used to translate the text from the source language to the target language. You can use its NLP APIS for language detection, text segmentation, named entity recognition, tokenization and many other tasks.
- Text Analysis API: It is used to derive meaning and insights from textual content.
- Cloud NLP API: It is used to improve capabilities of the application using natural language capacities. It allows you to carry various natural language processing functions like sentiment analysis and language detection. It is easy to use.
- Google Cloud Natural Language API: It allows you to extract beneficial insights from unstructured text. It allows you to perform entity recognition, sentiment analysis, content classification and syntax analysis in more than 700 predefined categories. It allows to perform text analysis in multiple languages.
Libraries used:
- Scikit-learn: It provides a wide range of algorithms for building machine learning models in Python.
- Natural language Toolkit (NLTK): NLTK is a complete toolkit for all NLP techniques.
- Pattern: It is a web mining module for NLP and machine learning.
- Text Blob: It provides an easy interface to learn basic NLP tasks like sentiment analysis, noun phrase extraction, or post-tagging.
- Quepy: Quepy is used to transform natural language questions into queries in a database query language.
- Spacy: Spacy is an open-source NLP library which is used for Data Extraction, Data Analysis, Sentiment Analysis, and Text Summarization.
- Gensim: Gensim works with large datasets and processes data streams.
Work done till now:
I have set the development environment already. I have contributed a patch and work on some other issues. I have gone through the documentation of APIs and libraries ,their functioning and their correlation with the project .
Timeline:
GSOC is around 12-week duration with 25 days of Community Bonding Period in addition. I will be fixing 20% of time in fixing issues so that I can get comfortable with the codebase.
60% time on enhancing the features of my project and if I can make project more innovative.
20% time on the features added.
Community Bonding Period:
Phase 1: During this phase I will be dealing with the college exams. Although the schedule isn’t officially released yet I am taking the worst-case scenario.Therefore I will be dedicating only 3-4 hours and after the exam time I will be increasing the project time period.
Phase 2:Preparing the test cases for the project and check the functionality of my project and what improvements are required and what can be done to make the project more innovative.
Phase 3:
It includes:
• Thorough testing of the project
• Preparing documentation for the added features
• A webcast on the final product
The above-mentioned timeline is flexible one is subjected to change overtime after further discussion during community bond period and due to other factors. I have planned a one-week cushion/gap to accommodate for any emergency and slowdown that may occur. Moreover, I will stay in touch with the mentor’s regularly and will seek code review from them and community after competition of every phase. After the GSOC period, I will contribute towards the project integration, and further maintenance and updates.
I am ready to work in any of the projects you will provide me with. I love to learn new things and will be happy to bring them into application purposes.
Internship Experience:
I have learned about python, various libraries used and socket drivers.
Academics:
Institute Name: Indira Gandhi Delhi Technical University for Women.
Relevant courses taken: Java, Python, HTML, CSS, JavaScript, Machine learning.
I am interested in open source development program because it will help me to acknowledge my skills and give an idea of industrial rules.
I have done my schooling from Doon Public School. I have attended the school for 12 years. My major at my school was researching on new fields.
The best paper I have read is on preventing sql attacks in stored procedures.
I will be in Delhi only in summers and I can give hours on weekdays and on weekends 10 hrs and more. Yes, I would like to co-author a research paper on my work on this project or any other project you suggest me to work on.
I don’t have got any idea currently about my college schedule. But I am willing a good amount of time to the project.
I have never applied to GSOC or any other open source organisation. This is my first time .
Why selected organization and Why project:
As a fresher, I need a platform to start my career, where I can learn a lot of new skills and enhance my knowledge which help me to grow professionally and do the best for your organization as well. I’ve gone through your company’s profile and I learned that your company encourages fresh talent and provides good work culture. I think it is a golden opportunity for me to work here and enhance my skills.
I have chosen this project because I have a prior knowledge on the requirements for this. Also, I have a prior knowledge on the prerequisites required for this. I have gone through the working and documentation project for this. I feel competition of this project can make human and machine interaction much easier which can contribute to the development part.
Why me?
I should be selected for this role because I have knowledge on this project and I have good analytical skills, which can lead to the development of a good project. I should be selected because I am ready to give my all in this project. I want to adopt the culture of google summer of code and want to be connected with this organisation after google summer of code as well .